
Dynamique du vol en environnement instationnaire et inhomogène
Présentation
Responsable du thème : Nicolas Vauchel
Cette thématique porte sur la conception d’outils et de méthodologies expérimentales, numériques et analytiques, destinés à caractériser les comportements des aéronefs à basse vitesse lorsqu’ils évoluent dans des environnements de vol perturbés ou hors des domaines de vol conventionnels.
Contexte
La dynamique du vol désigne l’ensemble des méthodes permettant de prédire l’évolution de l’attitude et de la trajectoire d’un aéronef. Pour réaliser ces prédictions, il convient de disposer d’un modèle mathématique décrivant les forces et moments aérodynamiques qui s’exercent sur le système. Ce modèle s’appuie sur des données expérimentales et/ou numériques et repose sur une structure mathématique adaptée à la problématique étudiée. La dynamique du vol est donc une thématique transverse entre l’aérodynamique, les mathématiques appliquées, la science de données et le contrôle.

En vol perturbé (domaine post-décroché, environnement perturbé), les écoulements autour des surfaces portantes deviennent hautement complexes, fortement instables et souvent très instationnaires. Les hypothèses simplificatrices classiques effectuées pour l’étude du vol normal peuvent ne plus être valables, et les modèles des forces et moments aérodynamiques peuvent devenir fortement non-linéaires et instationnaires. Il convient alors de sélectionner une structure de modèle adéquate pour décrire l’impact de ces écoulements complexes sur l’aéronef, ainsi que d’identifier et d’optimiser la définition des expériences et/ou simulations permettant d’acquérir les données sur lesquelles s’appuient ces modèles. Une fois un modèle aérodynamique établi, des outils sont également nécessaires pour la prédiction des comportements et pour la détermination de la stratégie de sortie des comportements dangereux qui résultent de l’étude de dynamique du vol.
Objectifs
L’objectif pour ce thème est d’étoffer la boîte à outils méthodologique et expérimentale du laboratoire pour répondre à plusieurs besoins:
- améliorer la robustesse des prévisions, dans des domaines de vol à risque,
- Intégrer le poids des incertitudes liées à la méconnaissance ou la simplification des structures de modèles,
- Développer des techniques d’analyse qui permettent d’optimiser et de guider l’exploration expérimentale pour déterminer au mieux les modèles de représentation par rapport aux attentes de leur exploitation.
L’utilisation de méthodes d’apprentissage automatisée ou de science de donnée en générale est un sujet de recherche au centre de la thématique.
Certains comportements, comme les vrilles ou les spirales, correspondent à des équilibres du système dynamique de vol.
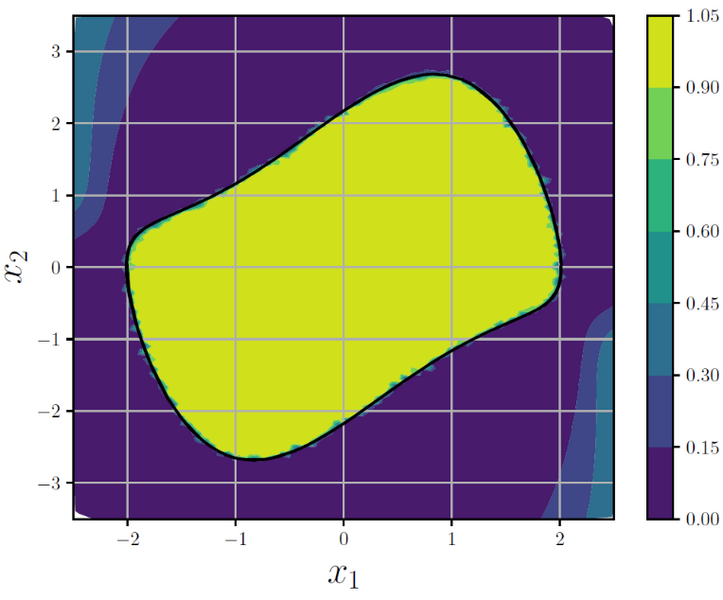
La théorie des bifurcations appliquée au système dynamique du vol non-linéaire offre alors une vision globale de l’ensemble des régimes accessibles à l’aéronef aux temps asymptotiques et permet d’analyser l’évolution de ces régimes ainsi que leur stabilité lorsqu’un paramètre de contrôle varie. Il serait particulièrement utile d’estimer les régions d’attraction associées à ces équilibres, correspondant à l’ensemble des conditions initiales tendant vers ce comportement aux temps asymptotiques. A cette fin, des approches d’apprentissage automatique et des techniques statistiques déjà exploitées dans le contexte de la bistabilité en turbulence, sont mises à l’épreuve.
Dans le cadre des travaux poursuivis sur l’analyse des événements extrêmes en milieu urbain (voir thème « turbulence »), notamment poursuivis par une thèse ONERA/Région, l’étude de la dynamique de vol des drones évoluant dans un environnement fortement perturbé est un axe de recherche. L’intégration de ces phénomènes dans la modélisation dynamique du vol constitue un point central de la recherche. Parallèlement, une méthode de reconstruction du champ aérologique de la canopée urbaine est développée. Celle‑ci combine les connaissances du champ a priori avec les mesures locales acquises in situ par le drone.
La formulation d’un modèle mathématique décrivant les forces et moments aérodynamiques s’appliquant sur un aéronef constitue une étape cruciale pour les études de dynamique du vol. Après avoir sélectionné une structure de modèle appropriée, un plan d’essais en soufflerie et/ou de simulations numériques est réalisé afin d’acquérir les données nécessaires à l’identification du modèle. Ce plan d’essais (ou de simulations) est classiquement défini a priori, avant même que le modèle ne soit construit. Dès lors, il n’est pas toujours aisé de s’assurer que la matrice d’essais couvre suffisamment les phénomènes d’intérêt que l’on souhaite modéliser. L’objectif de cet axe est d’étudier et de développer des techniques de guidage de l’expérimentation. La création d’un jumeau numérique (dans le cadre d'une thèse ONERA/Région) et l’utilisation de l’échantillonnage adaptative sont étudiées pour répondre à ces objectifs.
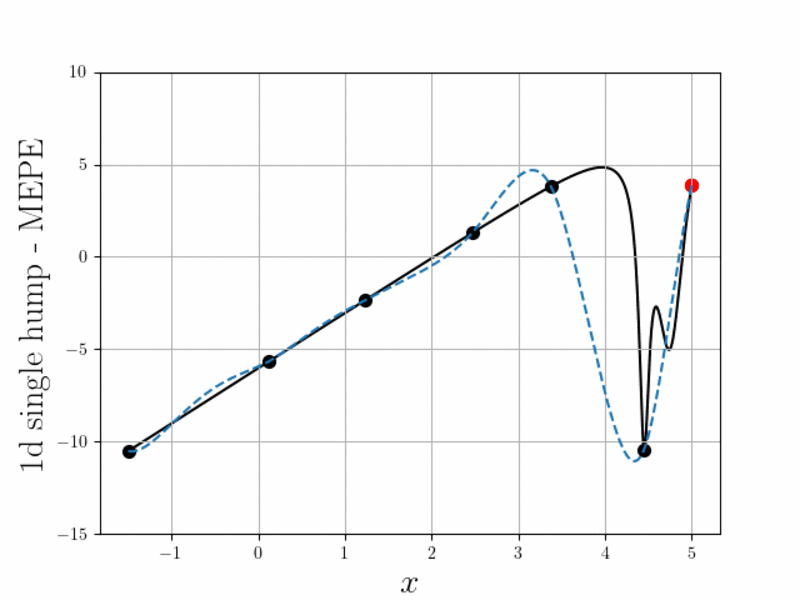
L’amélioration des modèles aérodynamiques afin d’intégrer un plus grand nombre d’effets constitue un axe de recherche du thème. Cette amélioration repose sur deux piliers :
- Enrichissement des coefficients aérodynamiques – la prise en compte de plus d’effets d’interactions entre les variables d’état et de contrôle (gouvernes, propulsion à hélices, etc.).
- Extension des équations de mouvement – l’incorporation des phénomènes supplémentaires, tels que la modélisation des rafales de vent et, plus généralement, la prise en compte de la turbulence atmosphérique.
Dans ce cadre, la modélisation de l’impact des rafales de vent sur les dirigeables fait partie des problématiques étudiées. Par ailleurs, une thèse ONERA‑Région porte sur une étude expérimentale de l’interaction aérodynamique entre les hélices de drones multirotors.
 et simulation d’attitude sur cette même géométrie à l’aide d’un modèle aérodynamique obtenu (à droite")
Le modèle aérodynamique, construit à partir de données expérimentales et numériques, comporte inévitablement des incertitudes liées à la précision et à la variabilité de ces mesures. En outre, le choix d’une structure simplifiée pour le modèle introduit une source supplémentaire d’incertitude, liée à la capacité de la formulation à capturer fidèlement les phénomènes physiques. Il est donc indispensable de quantifier l’ensemble des sources d’incertitude et de les propager à travers les équations non-linéaires de la dynamique du vol, afin d’évaluer leur influence sur les comportements prédits.
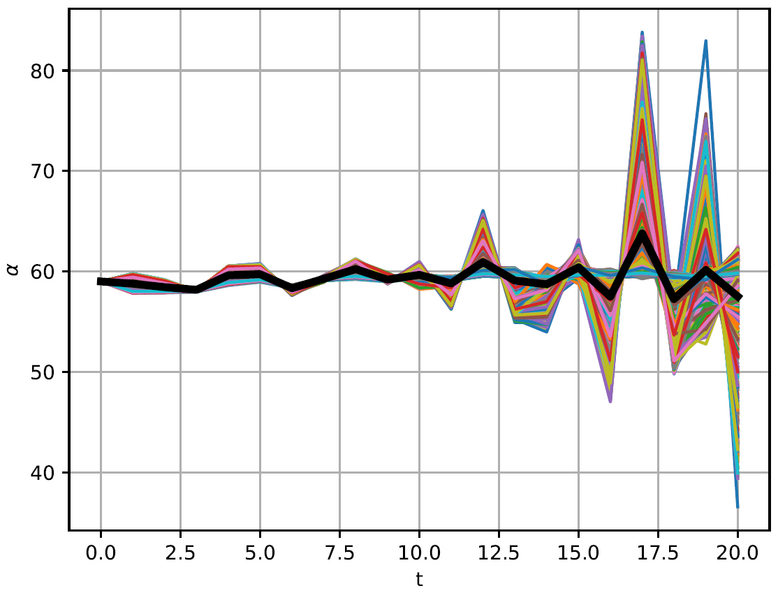
L’apprentissage par renforcement profond (Deep Reinforcement Learning) permet de concevoir une loi de commande à l’aide d’un réseau de neurones qui associe l’état du système aux actions de contrôle à sélectionner pour accomplir une tâche donnée. Le réseau est entraîné au cours de multiples itérations de la simulation, dans le but de maximiser une fonction de récompense conçue pour encourager le comportement souhaité. Dans le cadre de la dynamique du vol post‑décroché, l’étude porte sur l’utilisation de l’apprentissage par renforcement profond afin de déterminer une loi de commande capable d’assurer une sortie de vrille optimale. La fonction de récompense sera définie de manière à minimiser la perte d’altitude pendant la récupération.